Code Security
Compounding Context: The Missing Layer in SCA
Software Composition Analysis (SCA) has quietly become one of the most important, and most frustrating, disciplines in application security. The tooling has never been better. The signal quality has never been higher. And yet, the PRs still get ignored, the findings still pile up, and the security debt keeps compounding. Something is missing, and it isn’t more alerts.
This article explores what the next iteration of SCA looks like, why fixing it is harder than it looks, and how to build an architecture that finally closes the gap by building the context layer that makes all of your existing signals useful.
SCA Has Come a Long Way
When it was first introduced to the market, SCA started as a simple inventory problem. Identify what open source packages are in your codebase, check them against a database of known vulnerabilities, and report what you find. That was the whole job.
Direct dependencies were the original scope; packages your code explicitly imports. That problem was manageable. Then the industry recognized that transitive dependencies, often five to ten layers deep, were really the piece that accounted for the majority of real-world exposure. The blast radius of the problem expanded considerably.
The tooling adapted. Automated Pull Requests (PRs) started proposing version bumps. Findings surfaced directly in pull request workflows. IDE integrations flagged issues at code write time. Security stopped being a quarterly report handed to a separate team and started being part of the development loop.
This was a genuine and meaningful improvement. But something subtle broke along the way; developers stopped trusting the output.
The automated PRs are blind to the code they’re changing. A proposed version bump carries no knowledge of whether the upgrade will break the three call sites that use the affected function in non-standard ways. Developers learn this the hard way very quickly. They get burned once, a “safe” automated fix introduces a regression, and from that point forward the PRs get deprioritized.
Alert fatigue sets in, not because the findings are wrong, but because the proposed fixes lack the context required to act on them with confidence. To this day, the core output of SCA is still a list of findings with severity scores. Actionable in theory. Ignored in practice.
Advancing Risk Signals
The industry recognized that raw CVE lists with CVSS scores were insufficient for prioritization. High severity does not equal high risk in every codebase. So the vendors went to work building richer signals.
Reachability was the first major advancement. Static or dynamic call graph analysis to determine whether a vulnerable function is ever actually invoked in the execution path. If it isn’t called, the theoretical risk isn’t realized risk. This was a legitimate step forward.
Package breakability added another dimension. Changelog analysis, semver signals, and API surface change detection to estimate whether upgrading a dependency would introduce regressions.
Package health rounded out the set. Maintenance status, last commit recency, download trends, and community activity as a proxy for the long-term viability of a dependency.
These signals represent real improvement in prioritization quality. But they share a critical structural limitation; they are all computed at the package level, not the codebase level. And that distinction matters more than most people realize.
Reachability analysis degrades significantly for dynamic languages. Python’s duck typing, JavaScript prototype chains, and Ruby metaprogramming make static call graph construction unreliable. The signal you receive is probabilistic, not binary, but it’s rarely communicated that way. You get “reachable” or “not reachable”, instead of a more explicit “reachable with 60% confidence based on partial call graph coverage”. That missing confidence interval is where bad decisions get made.
It’s worth noting that the industry is moving toward gradual typing; both Python type hints and TypeScript specifically address this limitation. A statically typed codebase produces more reliable call graphs and therefore more trustworthy reachability signals. There’s also an interesting recursive opportunity here: an AI-assisted pre-pass that generates missing type annotations can harden dynamic codebases enough to make downstream reachability analysis more deterministic. Using AI to make the inputs to AI more reliable (akin to synthetic data used for model training or tuning).
Package breakability has its own version of this problem. It tells you the package changed. It cannot tell you whether your specific usage of that package will break. That requires knowing how your code calls it…which is codebase-level context that no vendor tool computes from the outside.
The net result is a more sophisticated alert that developers still cannot act on confidently. The blind PR problem isn’t solved. It’s better decorated.
The Combinatorial Limits of Enriched SCA
Imagine the following SCA workflow for a moment:
- Scan the codebase
- Enrich the findings with risk signals
- Pass everything to an LLM to generate fixes
On the surface this looks like a reasonable reduction of the problem. Fewer findings reach the LLM, and each one carries more context.
The hidden issue is that fix decisions aren’t made on individual signals in isolation. They’re made on the intersection of multiple signals simultaneously, and that intersection is combinatorially explosive.
SCA without codebase-level context is an NP-hard problem.
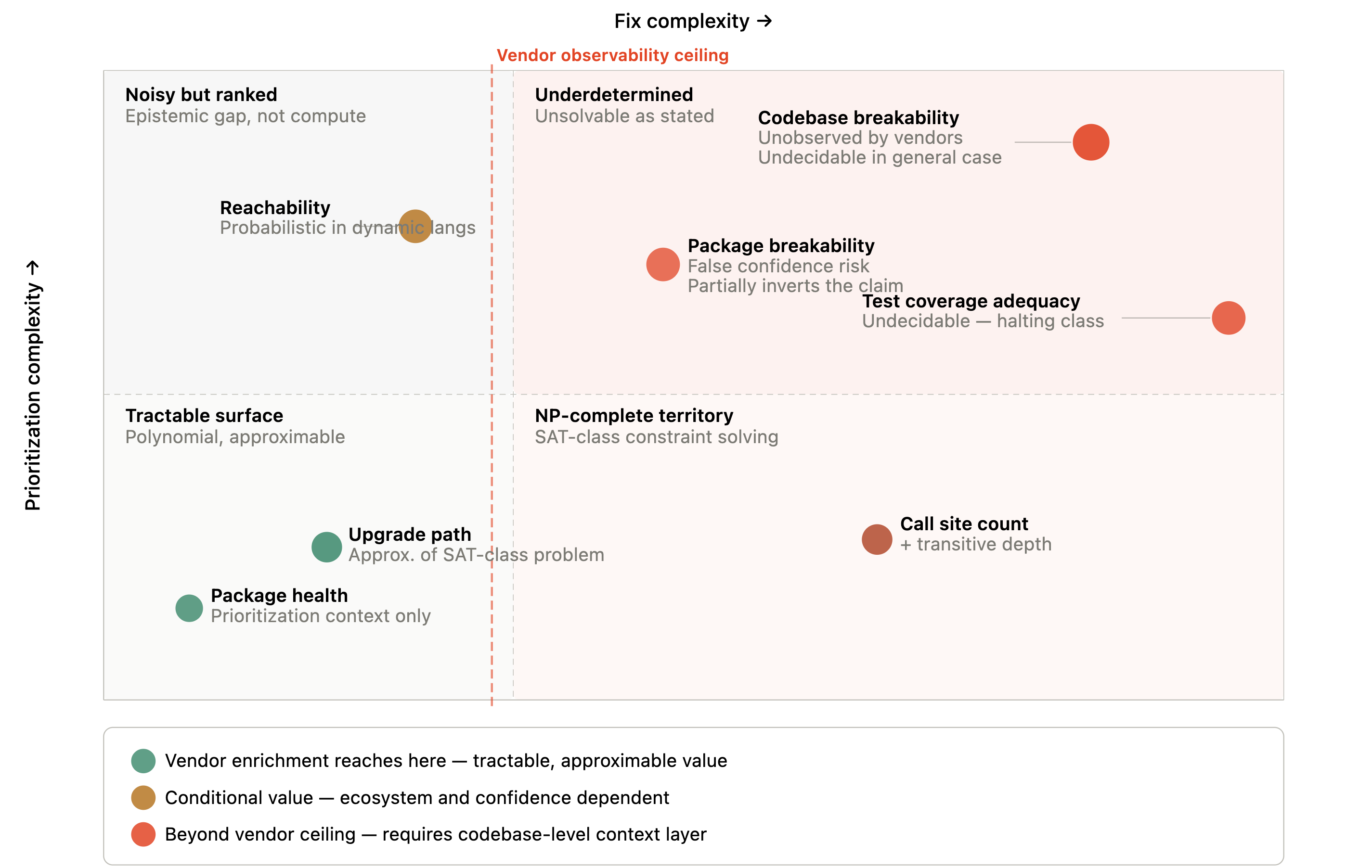
The prioritization dimension alone combines reachability (reachable / not reachable / unknown confidence), severity (CVSS score plus exploit maturity plus public proof-of-concept availability), and upgrade complexity (patch / minor / major / no available path).
The fix complexity dimension adds package-level breakability, codebase-level breakability (unobserved by any vendor tool), test coverage quality (also unobserved), number of affected call sites, and transitive dependency depth.
Even with conservative binning of each variable, the combined decision space runs into hundreds of meaningful combinations before accounting for ecosystem, team capacity, or architectural constraints.
Dependency constraint solving, finding a valid upgrade path across a full transitive dependency graph with version lock constraints, is formally NP-complete. It reduces to Boolean satisfiability (SAT). This is why package managers like pip and npm run SAT solvers internally and can time out or fail on sufficiently complex graphs. An upgrade path signal is an approximation of an NP-complete problem, not a solution to it.
Full interprocedural call graph construction, required for true reachability, is undecidable in the general case. For dynamic languages, this is a mathematical ceiling, not an engineering limitation.
To be precise, the LLM proposes a version based on semantic reasoning about usage and breakability; the package manager’s SAT solver validates whether that version is logically compatible with the full dependency graph. These are complementary operations; conflating them produces unreliable results.
The consequence is that vendor-driven enrichment merely scratches the surface of the issue. While they handle the more manageable aspects, the variables that are computationally difficult to solve, such as codebase-specific breakability, absolute reachability, and the sufficiency of test coverage, remain completely hidden from view.
There’s a more dangerous failure mode worth naming explicitly. Enriched-but-wrong signals passed to an LLM produce worse outcomes than raw noisy data. An LLM receiving a confident “low breakability” signal will not hedge, will not flag call sites for review, and will generate a clean-looking but potentially incorrect fix. Raw uncertain input at least triggers cautious reasoning. Precise-looking bad data outperforms vague good data at producing wrong decisions.
Layering Context: The Missing Dimension
The signals above answer which findings matter. They don’t answer what will happen when I fix them.
The missing layer is codebase-level context; how the vulnerable package is actually called, which modules depend on it, how data flows through it, what test coverage exists around those call sites, and what the downstream impact of a change would be.
Adding this context naively, passing entire codebases or large file sets into each LLM fix call, is computationally prohibitive and architecturally unsound. Token costs scale with codebase size and must be paid on every invocation.
A common objection as LLM context windows expand toward one million tokens by default, “why not just stuff the whole codebase into the prompt?”. The answer is cost. It’s not about the size of the context window, nor the ability to multi-shot prompt against the codebase, it’s whether you should pay to re-process the data on every single invocation. A one-million-token context passed to an LLM on every fix call is not an architecture. It’s a recurring tax with no compounding return.
The key insight is that codebase context is largely stable. The architecture of a system, the call patterns around a dependency, the module boundaries…these change slowly and incrementally, not continuously. This stability property means codebase context can be computed once, stored durably, and retrieved cheaply. The (initial) expensive analysis gets amortized across every future fix call rather than repeated each time.
Think about key pieces of an application. Authentication, database ORM, notification systems. These are core components of an application that are often built once and then infrequently changed. Sure, there are minor updates or bug fixes, but the overall component remains relatively unchanged.
Building the Cake: A Layered Context Architecture
Imagine that we need to assemble a cake, each layer is assembled in a different way (update frequency) with a distinct cost profile.
Layer 1: The Foundation
This layer is built once and built carefully. It includes the raw SCA scan output; all findings with full metadata, severity scores, CVE references, and dependency tree position. It includes a shallow clone of the repository, enough to capture file structure, module organization, import graphs, and configuration files without the full git history. And it includes security metadata: known exploit availability, EPSS scores, vendor advisories, and patch release timelines.
This layer is the most expensive to assemble and the most stable. It changes only when the codebase or the vulnerability database changes materially. Its quality directly determines the accuracy of everything above it. Do not rush it and do not truncate it.
Layer 2: Code-Level Intelligence
This is where the architecture separates from everything that came before it. Use an LLM to analyze the shallow clone and generate codebase-level context: what was built, how the major modules interact, how data flows through the system, and how the dependency graph maps to actual code execution paths.
Run at least two passes with a single model, or use two (different) specialized models. The first focuses on structural and architectural understanding; module boundaries, call graphs, data flow patterns. The second focuses on security-specific reasoning; vulnerability propagation paths, exploit prerequisites, fix blast radius. The reason two passes outperform one is attention dilution. A single model asked to simultaneously understand architecture and reason about security vulnerabilities splits its effective context window between two cognitively distinct tasks. Separating them allows each model to operate at full depth within its strongest reasoning domain.
Map each SCA finding to the specific call sites, modules, and data flows identified in the structural pass. This is the codebase-level reachability and breakability analysis that external vendor signals approximate but cannot ground in your specific execution paths.
Once all of this analysis is generated, we’ll need a place to store it. That storage requires a hybrid approach rather than a single database type. A graph database or code property graph handles reachability traversal. When you need to know what downstream modules are affected by a change to a utility function, you need to traverse actual edges in a call graph; not retrieve semantically similar documents.
Vector similarity will surface a module because it resembles the utility semantically. Only the graph structure tells you whether it actually calls it and is therefore in the blast radius. A vector store handles semantic vulnerability reasoning; retrieving contextually relevant prior findings, similar fix patterns, and related architectural context by meaning rather than by exact identifier.
The hybrid store becomes a compounding asset. Each new finding and its resolved context enriches both the graph edges and the vector embedding space, making future fix generation progressively cheaper and more accurate.
Layer 3: Daily Drift Correction
Instead of running a daily SCA scan looking just for security issues, we’ll establish a daily agent run that pulls commits since the last check and diffs them against the stored context layers. The agent’s core function is triage; not all commits are semantically meaningful to existing findings.
Changes fall into three buckets: irrelevant (no update needed), contextually adjacent (flag for review, minor enrichment update), and directly relevant (re-run Layer 2 analysis for affected modules and update stored enrichments). Source code changes to modules that appear in the call graph of an existing finding are directly relevant by definition.
Build artifacts require explicit inclusion in drift detection. Dockerfile changes affect the execution environment and may alter which code paths are reachable in production. Changes to package-lock.json or yarn.lock directly affect the resolved dependency graph and may introduce or resolve findings independent of the SCA scan cycle. CI/CD pipeline changes can alter what gets built and deployed, changing the effective attack surface. These aren’t edge cases; they’re the class of change most likely to produce silent drift in your security posture.
SCA scan results are also re-checked daily. New findings are immediately enriched using the existing context store, dramatically reducing the cost versus the initial build. These daily runs are thin layers…they cost a fraction of the initial build because they operate on diffs rather than full re-analysis.
Layer 4: Remediation Planning
With all layers populated, the LLM fix generation call operates with precise codebase-level context rather than package-level approximations.
Not all findings warrant the same level of automation confidence. A confidence threshold model governs the output. High-confidence findings, reachable, well-tested call sites, low blast radius, available upgrade path, proceed to automated fix generation. Lower-confidence findings generate a context-aware PR for human review rather than an autonomous commit.
Human-in-the-loop review is not a fallback for when the system fails. It’s a designed output tier for cases where the architecture correctly identifies that it lacks sufficient certainty to act autonomously.
Building this level of trust across a remediation system will unlock more autonomous remediation over time because the underlying signals will instill confidence that the fix won’t break anything along the way. This not only drives greater efficiency, but reduces the risk surface substantially in time.
The remediation plan distinguishes between two sequencing modes:
Prioritized triage addresses the highest-risk findings first; those that are reachable, exploitable, and upgradeable without high blast radius.
Inbox zero systematically resolves all findings, sequenced to minimize application breakage: leaf dependencies before packages others depend on, patch-level upgrades before major version changes in the same module, test-covered call sites before untested ones.
The latter is only viable when codebase-level breakability analysis gives sufficient confidence that the fix sequence won’t cascade. That confidence comes from the layers below.
The Payoff: Token Economics & Security Debt
Token Economics and Amortization
The initial build, Layers 1 and 2, is the most expensive operation in the system. For a moderate codebase, full two-pass enrichment runs approximately 1 million tokens, roughly $3 at current model pricing. The daily drift agent adds $0.06 per day. Total 90-day infrastructure investment: under $9.
The return side of that equation has two tracks.
On token efficiency: each enriched fix generation draws from the stored context store rather than re-processing the codebase, saving approximately 15,000 tokens per fix. At a typical finding rate of 12-15 findings per quarter, that’s $0.60 in direct token savings, modest on its own, but it compounds with every subsequent quarter at near-zero marginal cost.
On engineering time: manual triage and remediation of a single finding; reading the alert, mapping blast radius, testing the fix, managing the PR through review, runs 2 to 4 hours for a mid-complexity codebase. At 13 findings per quarter and a conservative $150 per engineer hour, the architecture reclaims between $3,900 and $7,800 in engineering capacity inside 90 days. Against a $9 infrastructure cost, the ROI ratio isn’t close.
The upfront cost is capital investment in a context asset that compounds. Every finding remediated, every call site mapped, every fix pattern stored makes the next enrichment cheaper and the next fix more precise. The architecture gets more valuable every quarter it runs.
And this is for a single repository. Most enterprises operate hundreds to thousands of them. At that scale, the question isn’t whether the architecture pays for itself, it’s how much security debt you’re accumulating every day you’re not running it.
Security Debt Paydown
The security payoff follows the same 90-day frame, and it’s the number a CISO takes to a board.
Without codebase-level context, industry reporting consistently places enterprise MTTR for open source vulnerabilities at 60 to 90 days; meaning a finding that arrives at the start of a quarter is statistically likely to still be open at the end of it. That open window is exploitable surface. Every day it stays open is a day an adversary can use it.
With prioritized triage driven by layered context, high-confidence findings, reachable, testable, low blast radius, move from detection to merged PR within a single sprint. Two weeks or less. The exploitable window shrinks by 75% or more for the findings that carry the most real-world risk.
Inbox zero sequencing extends that logic across the full finding backlog. By ordering fixes to minimize cascading breakage, leaf dependencies first, patch-level before major version changes, covered call sites before untested ones, the architecture enables systematic debt paydown without the application breakage risk that causes teams to stall. The backlog doesn’t just get prioritized. It gets closed.
The break-even on security debt is faster than the token ROI. The first high-severity finding that gets fixed in two weeks instead of two months pays for the architecture in risk reduction alone. Every finding after that is compounding return on a decision that has already paid off.
What Precise Remediation Actually Looks Like
The most tangible output of this architecture is not a faster fix. It’s a fundamentally different kind of fix artifact.
A standard automated PR says:
lodash upgraded from 4.17.20 to 4.17.21 to address CVE-2021-23337
A context-aware PR says:
lodash upgraded from 4.17.20 to 4.17.21 to address CVE-2021-23337; this function is reachable via UserService → DataProcessor → formatOutput().
three call sites are affected; test coverage exists at DataProcessorTest.js line 847 covering the primary call site
the remaining two call sites in LegacyReportBuilder are not covered and have been flagged for manual review
the SAT solver confirmed this version is compatible with the full dependency graph
That is the difference between a PR a developer ignores and a PR a developer merges with confidence.
It closes the loop that has been open since the beginning of automated SCA. The findings were always there. The signals improved over time. But the fix artifact never carried enough context to be trusted. This architecture makes the fix artifact as precise as the analysis that produced it; and it does it without requiring developers to re-litigate the context every time.
Making This Real
None of this is fully solved. The hybrid graph-vector store is not a commodity product you can stand up in an afternoon. The two-model pass approach requires deliberate prompt engineering and evaluation. The drift agent’s triage logic needs tuning for each codebase’s commit velocity and architecture. These are real engineering challenges.
But the directional argument is sound, and the technology required to execute it exists today. Graph databases, vector stores, shallow clone analysis, drift agents — none of this requires capabilities that aren’t already running in production environments. The architecture isn’t waiting on a breakthrough. It’s waiting on someone to assemble the pieces with intention.
The fundamental problem with enriched SCA, that it operates on package-level signals while fix quality is determined by codebase-level variables, is not a problem that more signals will solve.
It’s a structural problem that requires a structural answer.
Compounding context is that answer. Build the foundation carefully, generate the intelligence layer thoroughly, maintain it incrementally, and let the economics work in your favor. The security debt doesn’t have to compound forever.